Un système HPC peut avoir des milliers de nœuds et des milliers d’utilisateurs. Comment décider qui obtient quoi et quand ? Comment s’assurer qu’une tâche est exécutée avec les ressources dont elle a besoin ? Cette tâche est traitée par un type de logiciel spécial appelé scheduler ,sur un système HPC, l’ordonnanceur gère les tâches qui sont exécutées où et quand.
Le but premier de l’ordonnanceur de tâches est de réserver des ressources pour les calculs des utilisateurs afin de garantir que les calculs soient exécutés au mieux. Il empêche la surcharge d’un nœud de calcul donné et met les calculs en attente jusqu’à ce que les ressources soient disponibles.
Le second objectif de l’ordonnanceur est de surveiller l’utilisation pour assurer une distribution équitable des ressources HPC dans le temps. Les politiques de partage équitable empêchent un utilisateur ou un groupe donné de monopoliser l’ensemble du cluster pendant des périodes prolongées si les calculs d’autres utilisateurs sont en attente dans la file d’attente.
Sur Le cluster HPC-MARWAN, vous contrôlez vos calculs en utilisant un système de planification des tâches appelé Slurm qui gère et vous attribuer les ressources informatiques.
Attention
Soyez un bon utilisateur du cluster. N’exécutez pas les calculs sur des nœuds de connexion (login), car ce-ci peut avoir un impact sur les sessions et la connectivité de tous les autres membres du cluster.
Afin de faciliter l’utilisation de l’ordonnanceur, un certain nombre d’exemples de scripts relatifs aux applications installées sur HPC-MARWAN ont été créés (voir ici). En outre, des scripts simples ont été créés pour illustrer l’utilisation actuelle du HPC et pour aider à supprimer des calculs HPC.
Commandes communes de Slurm
Soumettre un script exécutable au système de mise en file d’attente :
sbatch script.sl
Liste des calculs en attente et en cours.
squeue -u$USER
Annuler un calcul en attente ou arrêterun calcul en cours.
scancel <job_id>
Vérifier le statut d’un calcul individuel (y compris les calculs échoués ou achevés).
sacct -j <job_id>
exemple :
sacct -j 61458 -o start,end
Start End
------------------- -------------------
2020-05-08T23:55:15 2020-05-09T01:55:44
2020-05-08T23:55:15 2020-05-09T01:55:45
Afficher les informations sur les nœuds et les partitions de Slurm.
sinfo [OPTIONS...] : pour visualiser les nœuds hors ligne (sinfo –R).
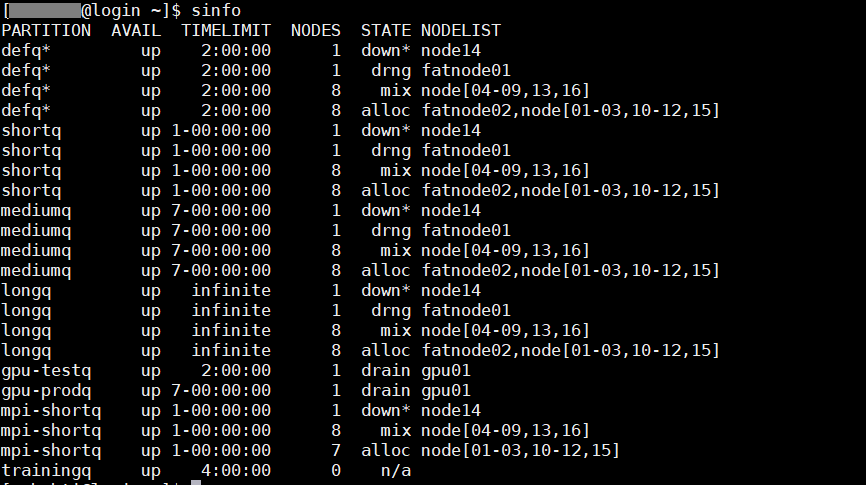
sinfo -o "%40N %10c %10m %25f"

Pour plus d’information sur les option de sinfo, taper la commande sinfo –help. Les options ci-dessus sont des abréviations de :
N = nom du noeud
c = nombre de cœurs
m = mémoire
f = caractéristiques, souvent ce sera l’architecture ou le type de gpu associé
Le %40 signifie 40 caractères pour ce champ.
Exécution d’un calcul batch
Afin de lancer un job sur l’HPC, vous êtes invités à préparer un script slurm https://slurm.schedmd.com/sbatch.html compatible avec l’application que vous souhaitez utiliser. Ce script shell appelé script de soumission enveloppe votre travail. Un script de soumission se compose de trois parties:
le programme qui doit exécuter le script. Il s’agit normalement de
#!/bin/bash.les « directives » qui indiquent à l’ordonnanceur comment configurer les ressources de calcul pour votre job. Ces lignes doivent apparaître avant toute autre commande ou définition, sinon elles seront ignorées.
La partie « script » proprement dite, c’est-à-dire les commandes que vous voulez faire exécuter par votre tâche .
Voici un exemple de script.sl qui exécute un job sur une unité centrale sur un seul nœud :
#!/bin/bash
#SBATCH --job-name=my_job
#SBATCH --ntasks=1 --nodes=1
#SBATCH --mem-per-cpu=5G
#SBATCH --partition=defq
#SBATCH --time=12:00:00
./myprog -p 20 arg1 arg2 arg3 ...
Pour soumettre ce job à l’ordonnanceur, nous utilisons la commande sbatch.
$ sbatch script.sl
Submitted batch job 36855
Pour vérifier l’état de notre travail, nous vérifions la file d’attente en utilisant la commande squeue -u yourUsername.
$ squeue -u yourUsernameJOBID USER ACCOUNT NAME ST REASON START_TIME TIME TIME_LEFT NODES
CPUS36856 yourUsername yourAccount example-job.sh R None 2017-07-01T16:47:02 0:11 59:49 1 1
Les directives d’un script
Comme le montre l’exemple ci-dessus, les « directives » sont composées de #SBATCH suivi des options Slurm. Les options les plus couramment utilisées sont les suivantes :
Option |
Abréviation |
Description |
–job-name |
-J |
Nom personnalisé du job |
–partition |
-p |
Partition sur laquelle le job sera exécuté (defq, shortq, mediumq, longq) |
–nodes |
-N |
Nombre total de nœuds |
–ntasks |
-n |
Nombre de « tâches ». A utiliser pour le calcul parallèle. |
–cpus-per-task |
-c |
Nombre de CPU alloués à chaque tâche |
–ntasks-per-node |
Nombre de « tâches » par nœud. A utiliser pour le calcul parallèle. |
|
–time |
-t |
|
–constraint |
-C |
Architecture spécifique des nœuds |
–mem-per-cpu |
Mémoire demandée par CPU (par exemple 10G pour 10 GB) |
|
–mem |
Mémoire requise par noeud (par exemple 40G pour 40 GB) |
|
–mail-user |
Adresse de courrier électronique |
|
–mail-type |
Contrôlez les courriels envoyés à l’utilisateur lors d’événements professionnels. Utilisez TOUS pour recevoir des notifications par e-mail au début et à la fin du job. |
Des options supplémentaires sont disponibles dans la documentation officielle de Slurm.
Exemple de script run.sl pour les applications installer sur HPC
Vous trouvez sur le lien suivant des exemples de script que vous pouvez utiliser ou s’inspirer d’eux pour écrire votre script slurm :https://github.com/rahimbouchra/hpc_samples .
Exemple de script java run.sl
#!/bin/bash
#SBATCH -J Java
#SBATCH --partition=mediumq
#SBATCH --time=0-36:00:00
#SBATCH --mem=32G
#SBATCH -o %N.%j.%a.out
#SBATCH -e %N.%j.%a.err
echo "Compiling "
javac TestHpc.java
echo "Running "
java TestHpc
echo "Done"
Example de Script python run.sl
#!/bin/bash
#SBATCH --job-name=myPythonjob
#SBATCH --partition=defq #partition de test limitée a 2h, changer à shortq mediumq ou longq selon durée estimée
#SBATCH -o %x-%j.out #messages de log
#SBATCH -e %x-%j.err #messages d'erreurs
echo "Running "
python testpython.py
echo "Done"
Puis le lancer avec sbatch run.sl
Interactive jobs
La soumission des jobs à Slurm se fait soit en mode interactif soit en mode batch, Les jobs interactifs permettent à un utilisateur d’interagir avec des applications en temps réel dans l’environnement HPC. Les utilisateurs peuvent exécuter des applications d’interface utilisateur graphique (GUI), exécuter des scripts ou exécuter d’autres commandes directement sur un nœud de calcul.
Les utilisateurs sont invités à réserver les ressources nécessaires (nœud de calcul, CPU …) pour leur calcul. Ceux-ci peuvent être exécutés de deux manières, via salloc et srun . Si vous voulez juste une seule session interactive sur un nœud de calcul, alors utiliser srun pour allouer des ressources pour une seule tâche et lancer un script
$ srun -N 1 -n 1 --pty bash –i
$ srun --nodes=1 --ntasks-per-node=1 --time=01:00:00 --pty bash -i
Ici, nous demandons un seul cœur sur un nœud interactif pendant une heure avec la quantité de mémoire par défaut.
Vous pouvez également allouer un seul nœud ou plusieurs noeuds à l’aide de la commande salloc, puis voir les nœuds qui vous ont été alloués à l’aide de la commande squeue, puis srun ou mpirun pour démarrer les tâches. Par exemple, vous connectez au nœud principal via la commande ssh et allouer un nœud dans le cluster comme suit :
$ salloc -N 1 bash
salloc: Granted job allocation 109512
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
109512 batch bash robh R 0:12 1 odin006
$ ssh -X ordin006
salloc / srun / sbatch prend en charge un large éventail d’options qui vous permettent de demander des nœuds, des processeurs, des tâches, des sockets, des threads, de la mémoire, etc. Si vous les combinez, SLURM essaiera de trouver une allocation raisonnable, donc par exemple si vous demandez 13 tâches et 5 nœuds ,SLURM satisfera votre demande . Voici ceux qui sont les plus susceptibles d’être utiles :
Option |
Description |
-n |
Nombre de tâches |
-N |
Nombre de nœuds à affecter. Si vous l’utilisez,vous pourriez également être intéressé par –tasks-per-node |
–tasks-per-node |
Tâches maximales à affecter par nœud si vous utilisez -N |
–cpus-per-task |
Attribuez des tâches contenant plusieurs CPU. Utile pour les jobs avec parallélisation de mémoire partagée |
-p, –partition |
Demandez une partition spécifique pour l’allocation des ressources.S’il n’est pas spécifié, la partitionpar défaut telle que désignée par l’administrateur système sera sélectionnée. |
-w |
Noms des nœuds à inclure - pour sélectionner un ou des nœuds particuliers |
–mem-per-cpu |
Utilisez ceci pour que SLURM vous attribue plus de mémoire que la quantité par défaut disponible par CPU |